
Workplan
READ-IT’s workplan contains six work-packages (WPs) that are all tightly intertwined. Coordination of the research and development activities (WP2, WP3 and WP4) is ensured by WP1, where interdisciplinary collaborative discussions will foster synergy between the disciplines involved and help maximize impact. Achievements of the research and development activities will be handled and advertised within WP5, devoted to dissemination of results and community engagement at large.
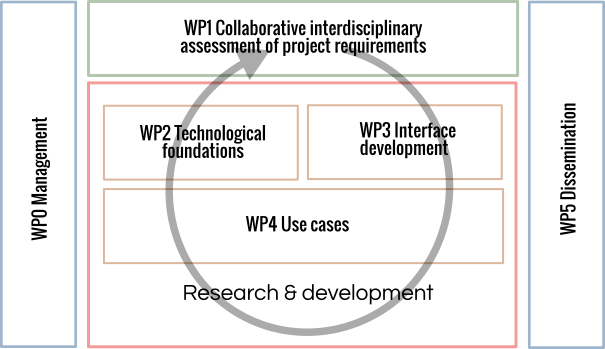
WP0 Management [M1-M36 Le Mans Université Lead] will ensure an efficient management of the project. Project management covers contractual, administrative and financial issues as well as communication, ethical and risk management within the consortium. It includes communication inside and outside the consortium. Main tasks are: setting up project meetings, project reporting, coordination of dissemination and of communication.
WP 1 Collaborative interdisciplinary assessment of project requirements [M1-M30 Le Mans Université Lead] will be in charge of determining user requirements and interface specifications for READ-IT by bringing together the expertise of ICT and humanities researchers through a series of meetings. Requirements will concern all aspects of READ-IT, encompassing data requirements (e.g., reusing data from national bibliographies), functional requirements (e.g., the system must be able to extract named entities from a text and use them to annotate the reading experience), interface requirements (e.g., the online interactive map for geolocated data should have a slider for filtering data belonging to a specific historical range), as well as other non-functional requirements (e.g., new data must not make existing data inconsistent). WP1 will in particular deliver final quality-assured, validated, open-source end-user specifications and full documentation that will be open for future reuse.
WP2 Technological foundations [M1-M30 IRISA Lead] gathers activities related to the development of semantic web and multimedia content mining technology, on which interfaces will be developed. WP2 is fueled with specifications established in WP1 in collaboration with all HS, DH and ICT partners. It delivers technology, mostly made available as APIs, for integration in WP3. WP2 will design, implement and publish the formal model in which project data will be stored, published and searched for, in accordance with semantic Web standards. Data crawling methods will be implemented for key languages (French, English, German and Italian), primarily addressing the identification of textual resources with extension to images, combining ontological knowledge, text mining technology and image retrieval. WP2 will address content-based description of resources and linking technology to facilitate curation and description.
WP3 Interfaces [M1-M36 Universiteit Utrecht Lead] will focus on allowing HSS researchers to make efficient and sustainable use of complex multilayered cultural datasets. The goal of WP3 will be to reduce HSS researchers’ effort to deploy these complex datasets and text corpora for analysis. It will develop a user-friendly interface for querying the data, incorporating the tools developed by WP2. Based on specifications from WP1 and building on achievements in WP2, WP3 will implement a model that facilitates connections between multiple datasets and contextualization algorithms, providing cross-links between corpora, and linking semantic features such as entities, relations and events. WP3 will also design the structure, navigation and general appearance of the interfaces. The tool will encompass a search and explore application, dashboard visualizations to accommodate explorative analytics and fine tuning of queries, an API for developers as well as a web interface on the data for the general public (within the limits given by possible copyrights on data as well as ERC privacy and data protection regulations). It is also here that the public engagement apps (PEA) will be developed.
WP4 Uses cases [M12-M36 Institute of Czech Literature Lead] groups all use-cases testing how READ-IT answers end-users needs and, in particular, HSS research on reading experiences by examining the usability of READ-IT for: (1) the lexicographic analysis and interpretation of multilingual printed and handwritten textual sources in German, English, French and Italian (18-20th); (2) the identification of reading education in Eastern European contexts (CR 20th C); (3) the reconstruction of intellectual and literary reading practices (FR-DE 18th to 20th C); (4) the discovery of experiences of blind and partially sighted readers; (5) the observation of self-referencing across young readers communities (CR-UK 20-21st C); (6) the characterization of “stalking” as a contemporary form of reading on social media (FR-SP 21st C). WP4 builds on WP3 and will provide feedback to WP1-2. It will also set up new methodologies for documenting and editorializing knowledge about Cultural Heritage.
WP5 Dissemination [M6-M36 The Open University Lead] will work with the other WPs, APs, and named cultural institutions, third party organizations, charities, foundations and community groups. It will disseminate peer-reviewed research emerging from the use-case studies (WP4), digital tools and technologies from the interface work (WP3), as well as data models, ontologies and software developed in WP2. It proposes a robust, highly integrated and accountable model for both academic and non-academic dissemination as well as communication.